
아래의 책을 정리했습니다.
https://product.kyobobook.co.kr/detail/S000201399476
스프링으로 시작하는 리액티브 프로그래밍 | 황정식 - 교보문고
스프링으로 시작하는 리액티브 프로그래밍 | *리액티브 프로그래밍의 기본기를 확실하게 다진다*리액티브 프로그래밍은 적은 컴퓨팅 파워로 대량의 요청 트래픽을 효과적으로 처리할 수 있는
product.kyobobook.co.kr
Cold Sequence와 Hot Sequence
Cold와 Hot 각각 차가운, 뜨거운 이라는 뜻입니다.
이를 컴퓨터 시스템에 적용하면 이해하기 어려울 수 있습니다. 대표적인 예로 Hot swap이나 Hot deploy라는 용어가 있습니다. Hot swap은 전원이 켜져 있는 상태에서 디스크의 장치를 교체할 때, 재시작 없이 장치를 인식하는 것을 의미합니다. Hot deloy는 서버를 재시작하지 않고 프로그램의 변경 사항을 적용할 수 있는 것입니다.
즉, Hot은 처음부터 다시 시작하지 않고 같은 작업이 반복되지 않습니다. 반면에, Cold는 처음부터 다시 시작해야하고, 새로 시작하기 때문에 같은 작업이 반복됩니다.
Cold Sequence
Cold Sequence는 Subscriber가 구독할 때마다 데이터 흐름이 처음부터 다시 시작되는 Sequence입니다.
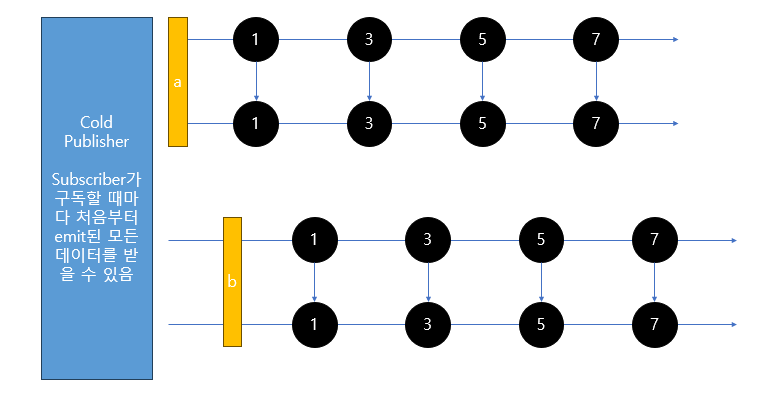
아래는 마블 다이어그램으로 표현한 Cold Sequence를 나타내는 타임라인입니다.
위쪽의 Subscriber A가 구독하면 Publisher는 4개의 데이터를 emit 합니다.
아래의 Subscriber B가 구독하면 Publisher는 4개의 데이터를 emit 합니다.
두 Subscriber의 구독 시점이 다르지만 A와 B는 동일한 데이터를 받고 있습니다.
결과적으로 Cold Sequence는 Suquece 타임라인이 구독할 때마다 하나씩 더 생깁니다.
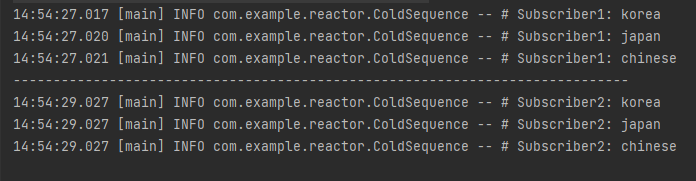
fromIterable() 을 사용하여 List로 전달받은 데이터 소스를 emit 하는 예제입니다.
Subscriber1의 결과 처리 후, 2초의 대기 시간을 갖고 Subscriber2의 결과를 처리하고 있습니다.
@Slf4j
public class ColdSequence {
public static void main(String[] args) throws InterruptedException {
Flux<String> coldFlux = Flux
.fromIterable(Arrays.asList("KOREA", "JAPAN", "CHINESE"))
.map(String::toLowerCase);
coldFlux.subscribe(country -> log.info("# Subscriber1: {}", country));
Thread.sleep(2000L);
System.out.println("-----------------------------------------------------------------------------");
coldFlux.subscribe(country -> log.info("# Subscriber2: {}", country));
}
}
두 Subscriber 모두 모든 Flux의 데이터를 emit 받아 처리하는 것을 확인할 수 있습니다.
Hot Sequence
Cold Sequence의 경우에는 구독이 발생할 때마다 Sequence의 타임라인이 처음부터 새로 시작하기 때문에 Subscriber는 구독 시점과 상관없이 데이터를 처음부터 다시 전달받을 수 있습니다.
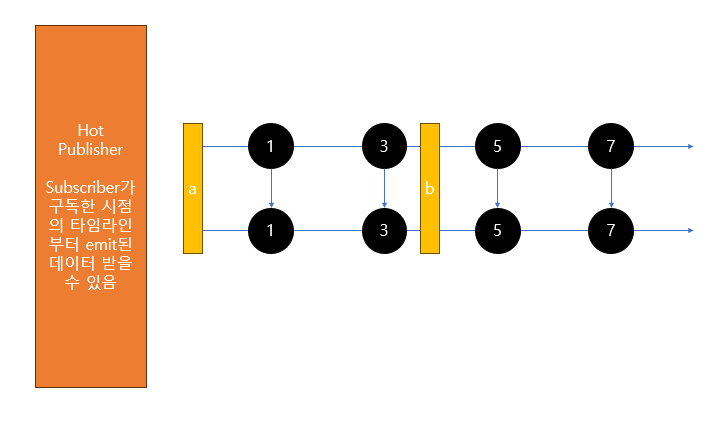
반면에 Hot Sequence의 경우에는 구독이 발생한 시점 이전에 Publisher로부터 emit된 데이터는 Subscriber가 전달받지 못하고 구독 발생 시점 이후에 emit된 데이터만 전달받을 수 있습니다.
아래는 Hot Sequence의 개념을 마블 다이어그램으로 표현한 것입니다.
Hot Sequence는 구독이 아무리 많이 발생해도 Publisher가 데이터를 처음부터 emit 하지 않습니다.
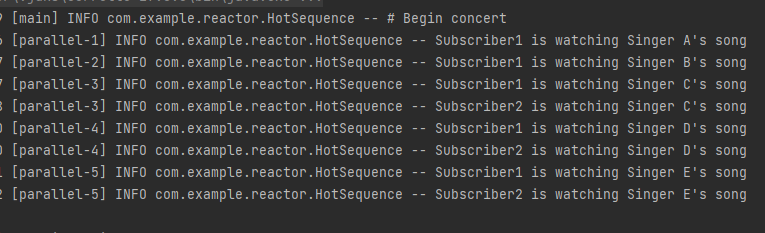
Hot Sequence의 의미를 쉽게 이해할 수 있는 예제입니다.
콘서트장에 가수 A~E까지가 오고 1초씩 노래를 부릅니다. 관객 1은 콘서트장에 처음부터 있었고, 2는 2.5초 뒤에 콘서트장에 입장했습니다.
delayElements() 는 데이터 소스로 입력된 각 데이터의 emit을 지연시키는 Operator입니다.
share() 는 Cold Sequence를 Hot Sequence로 동작하게 하는 Operator입니다. 여러 Subscriber가 하나의 원본 Flux를 공유하는 역할을 합니다.
@Slf4j
public class HotSequence {
public static void main(String[] args) throws InterruptedException {
String[] singers = {"Singer A", "Singer B", "Singer C", "Singer D", "Singer E"};
log.info("# Begin concert");
Flux<String> concertFlux = Flux
.fromArray(singers)
.delayElements(Duration.ofSeconds(1))
.share();
concertFlux.subscribe(
singer -> log.info("Subscriber1 is watching {}'s song", singer)
);
Thread.sleep(2500L);
concertFlux.subscribe(
singer -> log.info("Subscriber2 is watching {}'s song", singer)
);
Thread.sleep(3000L);
}
}
코드 결과로, Subscriber 1은 원본 Flux의 모든 데이터를 emit 하고 있고, Subscriber 2는 원본 Flux가 emit 한 데이터 중 singer A, singer B는 전달받지 못했습니다.
그리고 실행 결과에서 main 스레드와 parallel-1, parallel-2, parallel-3, parallel-4 스레드가 실행된 것을 볼 수 있습니다. 이는 delayElements() Operator의 디폴트 스레드 스케줄러가 parallel이기 때문입니다.
스케줄러에 대해서는 다음에 자세히 알아보도록 하겠습니다.
Http 요청에서의 Hot, Cold Sequence
Hot Sequence의 경우에는 Mono에 cache() Operator를 사용합니다.
cache() Opearator는 Cold Sequence로 동작하는 Mono를 Hot Sequence로 변경해 주고 emit된 데이터를 캐시한 뒤, 구독이 발생할 때마다 캐시된 데이터를 전달합니다. 결과적으로 캐시된 데이터를 전달하기 때문에 구독이 발생할 때마다 Subscriber는 동일한 데이터를 전달받게 됩니다.
이를 대표적으로 잘 활용할 수 있는 예는 Rest API 요청을 위해 인증 토큰이 필요한 경우입니다. getAuthToken() 이라는 메서드를 호출해서 API 서버로부터 인증 토큰을 전달받는다면 토큰이 만료되기 전까지 해당 인증 토큰을 사용해서 인증이 필요한 API 요청에 사용할 수 있습니다. 그러나 getAuthToken() 메서드 호출 시마다 매번 새로운 인증 토큰을 전송하게 되면 불필요한 요청이 발생할 것입니다. 이를 방지하기 위해 cache() Operator를 사용해 캐시된 인증 토큰을 사용하여 효율적인 동작을 구성할 수 있습니다.
Backpressure
Backpressure은 Publisher가 끊임없이 emit하는 무수히 많은 데이터를 적절하게 제어하여 데이터 처리에 과부하가 걸리지 않도록 제어하는 것입니다. 사실, Publisher만 제어하는 것이 아닌 Upstream Publisher로부터 데이터를 전달받은 모든 Downstream Publisher를 제어한다는 의미를 내포하고 있습니다.
데이터 개수 제어
첫 번째 방식은 Subscriber가 적절히 처리할 수 있는 수준의 데이터 개수를 Publisher에게 요청하는 것입니다. Subscriber가 request() 메서드를 통해 적절한 데이터 개수를 요청하는 방식입니다.
hookOnSubscribe() 메서드는 Subscribe 인터페이스에 정의된 onSubcribe를 대신해 구독 시점에 request() 를 호출해서 최초 데이터 요청 개수를 제어합니다.
hookOnNext() 메서드는 Subscribe 인터페이스에 정의된 onNext를 대신해 Publisher가 emit한 데이터를 전달받아 처리한 후, Publisher에게 또다시 데이터를 요청하는 역할을 합니다. 이 때 역시 request() 를 호출해 데이터 요청 개수를 제어합니다.
@Slf4j
public class Request {
public static void main(String[] args) {
Flux.range(1, 5) // 1부터 5까지 1씩 증가한 데이터 emit
.doOnRequest(data -> log.info("# doOnRequest : {}", data))
.subscribe(new BaseSubscriber<Integer>() {
@Override
protected void hookOnSubscribe(Subscription subscription) {
request(1); // 데이터를 하나씩 보내주기를 요청
}
@SneakyThrows
@Override
protected void hookOnNext(Integer value) {
Thread.sleep(2000L);
log.info("# hookOnNext: {}", value);
request(1);
}
});
}
}

Backpressure 전략 사용
| Ignore 전략 | Backpressure를 적용하지 않는다, |
| Error 전략 | Downstream으로 전달할 데이터가 버퍼에 가득 찰 경우, exception 발생 |
| Drop 전략 | Downstream으로 전달할 데이터가 버퍼에 가득 찰 경우, 버퍼 밖에서 대기하는 먼저 emit된 데이터부터 drop 시킴 |
| Latest 전략 | Downstream으로 전달할 데이터가 버퍼에 가득 찰 경우, 버퍼 밖에서 대기하는 가장 최근 emit된 데이터부터 버퍼에 채우는 전략 |
| Buffer 전략 | Downstream으로 전달할 데이터가 버퍼에 가득 찰 경우, 버퍼 안에 있는 데이터부터 drop 시키는 전략 |
'🍀spring' 카테고리의 다른 글
| [Spring] Project Reactor - Reactor와 마블 다이어그램 (1) | 2025.03.10 |
|---|---|
| [Spring] 리액티브 프로그래밍 - Blocking I/O 와 Non-Blocking I/O (0) | 2025.03.02 |
| [Spring] 리액티브 프로그래밍 - 리액티브 스트림즈 (0) | 2025.03.02 |