
안녕하세요. 저번 게시글에서는 다대일, 일대다, 일대일, 다대다 매핑에 대해서 알아보았는데요. 이번에는 그 외에 상속 매핑, 복합 키, 조인 클래스 등에 대해 알아보려 합니다.
김영한님의 자바 ORM 표준 JPA 프로그래밍을 읽고 정리했습니다.
상속 관계 매핑
관계형 데이터베이스에는 객체지향 언어에서 다루는 상속 개념이 없다. 대신에 슈퍼타입 서브타입 관계라는 모델링 기법이 객체의 상속 개념과 가장 유사하다.
ORM에서 이야기하는 상속 관련 매핑은 객체의 상속 구조와 데이터베이스 슈퍼타입, 서브타입 관계를 매핑하는 것이다.
슈퍼타입 서브타입 논리 모델을 실제 물리 모델인 테이블로 구현할 때는 3가지 방법을 선택할 수 있다.
조인 전략, 단일 테이블 전략, 구현 클래스마다 테이블 전략이다.
이 방법들에 대해 알아보려 한다.
조인 전략 - 각각의 테이블로 변환
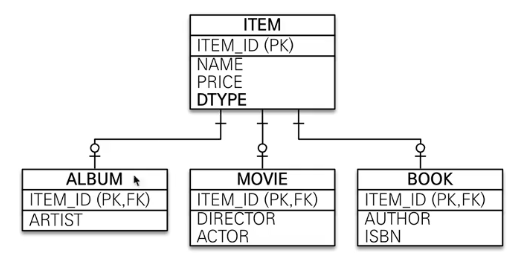
조인 전략은 아래 그림과 같이 엔티티 각각을 모두 테이블로 만들고 자식 테이블이 부모 테이블의 기본 키를 받아서 기본 키 + 외래 키로 사용하는 전략이다. 따라서 조회할 때 조인을 자주 사용한다.
여기서 주의할 점이 있다. 객체는 타입으로 구분할 수 있지만 테이블은 타입의 개념이 없다. 따라서 타입을 구분하는 컬럼을 추가해야 한다. 여기서는 DTYPE 컬럼을 구분 컬럼으로 사용했다.
@Entity
@Inheritance(strategy = InheritanceType.JOINED)
@DiscriminatorColumn(name = "DTYPE")
public abstract class Item {
@Id @GeneratedValue
@Column(name = "ITEM_ID")
private Long id;
private Strign name;
private int price;
}
@Entity
@DiscriminatorValue("A")
public class Album extends Item {
private Strign artist;
}
@Entity
@DiscriminatorValue("M")
public class Movie extends Item {
private String director;
private String actor;
}
@Inheritance(strategy = InheritanceType.JOINED) : 상속 매핑은 부모 클래스에 @Inheritance를 사용해야 한다. 그리고 매핑 전략을 지정해야 하는데 여기서는 조인 전략을 사용하여 JOINED을 사용했다
@DiscriminatorColumn(name = "DTYPE") : 부모 클래스에 구분 칼럼을 지정한다. 이 컬럼으로 저장된 자식 테이블을 구분할 수 있다. 기본값이 DTYPE이므로 @DiscriminatorColumn으로 줄여서 사용할 수 있다.
@DiscriminatorValue("M") : 엔티티를 저장할 때 구분 컬럼에 입력할 값을 지정한다. 만약 영화 엔티티를 저장하면 구분 컬럼인 DTYPE에 값 M이 저장된다.
기본값으로 자식 테이블은 부모 테이블의 ID 컬럼명을 그대로 사용하는데, 만약 자식 테이블의 기본 키 컬럼명을 변경하고 싶으면 @PrimaryKeyJoinColumn 을 사용하면 된다.
@Entity
@DiscriminatorValue("B")
@PrimaryKeyJoinColumn(name = "BOOK_ID")
public class Book extends Item {
private String author;
private String isbn;
}
조인 전략의 장점
- 테이블이 정규화된다.
- 외래 키 참조 무결성 제약조건을 활용할 수 있다.
- 저장공간을 효율적으로 사용한다.
조인 전략의 단점
- 조회할 때 조인이 많이 사용되므로 성능이 저하될 수 있다.
- 조회 쿼리가 복잡하다.
- 데이터를 등록할 INSERT 쿼리를 두 번 실행한다.
특징
- JPA 표준 명세는 구분 컬럼을 사용하도록 하지만 하이버네이트를 포함한 몇몇 구현체는 구분 컬럼 없이도 동작한다.
관련 어노테이션
@PrimaryKeyJoinColumn, @DiscriminatorColumn, @DiscriminatorValue
단일 테이블 전략 - 통합 테이블로 변환
단일 테이블 전략은 이름 그대로 테이블을 하나만 사용하는 전략이다. 그리고 구분 컬럼(DTYPE)으로 어떤 자식 데이터가 저장되었는지 구분한다. 조회할 때 조인을 사용하지 않으므로 일반적으로 가장 빠르다.

@Entity
@Inheritance(strategy = InheritanceType.SINGLE_TABLE)
@DiscriminatorColumn(name = "DTYPE")
public abstract class Item {
@Id @GeneratedValue
@Column(name = "ITEM_ID")
private Long id;
private String name;
private int price;
}
@Entity
@DiscriminatorValue("A")
public class Album extends Item {}
@Entity
@DiscriminatorValue("M")
public class Movie extends Item {}
@Entity
@DiscriminatorValue("B")
public class Book extends Item {}
@InheritanceType.SINGLE_TABLE : 단일 테이블 전략을 사용하게 된다. 테이블 하나에 모든 것을 통합하므로 구분 컬럼을 필수로 사용해야 한다.
단일 테이블 전략 장점
- 조인이 필요 없으므로 일반적으로 조회 성능이 빠르다.
- 조회 쿼리가 단순하다.
단일 테이블 전략 단점
- 자식 엔티티가 매핑한 컬럼은 모두 null을 허용해야 하낟.
- 단일 테이블에 모든 것을 저장하므로 테이블이 커질 수 있다. 그러므로 상황에 따라서는 조회 성능이 오히려 느려질 수 있다.
특징
- 구분 컬럼을 무조건 사용해야 한다. @DiscriminatorColumn을 꼭 설정해야 한다.
- @DiscriminatorValue를 지정하지 않으면 기본으로 엔티티 이름을 사용한다.
구현 클래스마다 테이블 전략 - 서브타입 테이블로 변환
구현 클래스마다 테이블 전략은 자식 엔티티마다 테이블을 만든다. 그리고 자식 테이블 각각에 필요한 컬럼이 모두 있다.

@Entity
@Inheritance(strategy = InheritanceType.TABLE_PER_CLASS)
@DiscriminatorColumn(name = "DTYPE")
public abstract class Item {
@Id @GeneratedValue
@Column(name = "ITEM_ID")
private Long id;
private String name;
private int price;
}
@Entity
@DiscriminatorValue("A")
public class Album extends Item {}
@Entity
@DiscriminatorValue("M")
public class Movie extends Item {}
@Entity
@DiscriminatorValue("B")
public class Book extends Item {}
@Inheritance(strategy = InheritanceType.TABLE_PER_CLASS) 를 사용하면 구현 클래스마다 테이블 전략을 사용한다. 이 전략은 자식 엔티티마다 테이블을 만들며, 일반적으로는 추천하지 않는 전략이다.
구현 클래스마다 테이블 전략 장점
- 서브 타입을 구분해서 처리할 때 효과적이다.
- not null 제약조건을 사용할 수 있다.
구현 클래스마다 테이블 전략 단점
- 여러 자식 테이블을 함께 조회할 때 성능이 느리다. (SQL에 UNION 사용)
- 자식 테이블을 통합해서 쿼리하기 어렵다.
특징
- 구분 컬럼을 사용하지 않는다.
- 이 전략은 데이터베이스 설계자와 ORM 전문가 둘 다 추천하지 않는 전략이다.
@MappedSuperclass
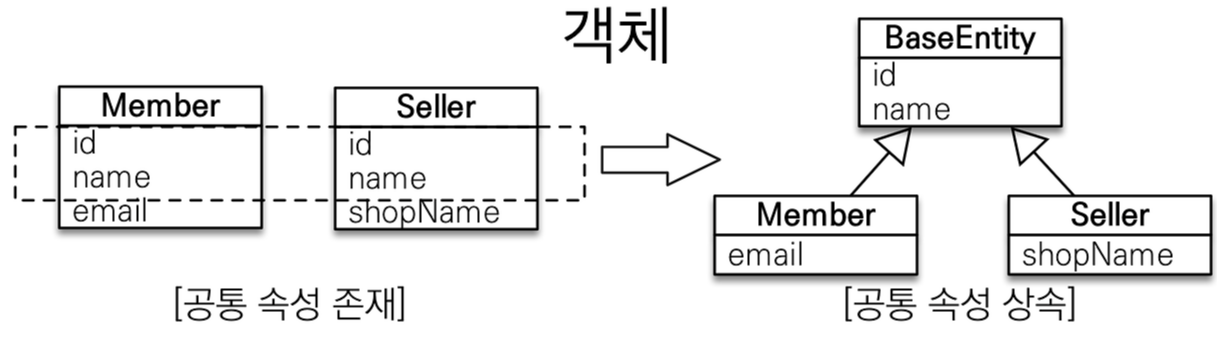
부모 클래스는 테이블과 매핑하지 않고 부모 클래스를 상속받는 자식 클래스에게 매핑 정보만 제공하고 싶으면 @MappedSuperclass를 사용하면 된다.
@MappedSuperclass는 비유하자면 추상 클래스와 비슷한데 @Entity는 실제 테이블과 매핑되지만 @MappedSuperclass는 실제 테이블과 매핑되지 않는다. 단순히 매핑 정보를 상속할 목적으로만 사용된다.
@MappedSuperclass
public abstract class BaseEntity {
@Id @GeneratedValue
private Long id;
private String name;
}
@Entity
public class Member extends BaseEntity {
// id, name 상속
private String email;
}
@Entity
public class Seller extends BaseEntity {
// id, name 상속
private String shopName;
}BaseEnity에는 객체들이 주로 사용하는 공통 매핑 정보를 정의했다. 그리고 자식 엔티티들은 상속을 통해 BaseEntity의 매핑 정보를 물려받았다.
부모로부터 물려받은 매핑 정보를 재정의하려면 @AttributeOverrides나 @AttributeOverride를 사용하고, 연관관계를 재정의하려면 @AssociationOverrides나 @AssociationOverride를 사용한다.
부모에게 상속받은 id 속성의 컬럼명을 MEMBER_ID로 재정의했다.
@Entity
@AttributeOverride(name = "id", column = @Column(name = "MEMBER_ID"))
public class Member extends BaseEntity {}
둘 이상을 재정의하려면 아래와 같이 @AttributeOverrides를 사용하면 된다.
@Entity
@AttributeOverrides({@AttributeOverride(name = "id", column = @Column(name = "MEMBER_ID")),
@AttributeOverride(name = "name", column = @Column(name = "MEMBER_NAME"))
})
public class Member extends BaseEntity {}
@MappedSuperclass 특징
- 테이블과 매핑되지 않고 자식 클래스에 엔티티의 매핑 정보를 상속하기 위해 사용한다.
- @MappedSuperclass로 지정한 클래스는 엔티티가 아니므로 em.find()나 JPQL에서 사용할 수 없다.
- 이 클래스를 직접 생성해서 사용할 일은 거의 없으므로 추상 클래스로 만드는 것을 권장한다.
- 이를 사용하면 등록일자, 수정일자, 등록자, 수정자 같은 여러 엔티티에서 공통으로 사용하는 속성을 효과적으로 관리할 수 있다.
복합 키와 식별 관계 매핑
복합 키를 매핑하는 방법과 식별 관계, 비식별 관계를 매핑하는 방법을 알아보자.
식별 관계 VS 비식별 관계
식별 관계 : 부모 테이블의 기본 키를 내려받아서 자식 테이블의 기본 키 + 외래 키로 사용하는 관계다.
비식별 관계 : 부모 테이블의 기본 키를 받아서 자식 테이블의 외래 키로만 사용하는 관계다.
비식별 관계에는 필수적 비식별 관계와 선택적 비식별 관계로 나눈다.
필수적 비식별 관계는 외래 키에 null을 허용하지 않고 연관관계를 필수적으로 맺어야 한다.
선택적 비식별 관계는 외래 키에 null을 허용하며 연관관계를 맺을지 말지 선택할 수 있다.
식별 관계와 비식별 관계를 어떻게 매핑하는지 알아보자.
복합 키 - 비식별 관계 매핑
둘 이상의 컬럼으로 구성된 복합 기본 키는 별도의 식별자 클래스를 만들어서 사용해야 한다.
JPA는 영속성 컨텍스트에 엔티티를 보관할 때 엔티티의 식별자를 키로 사용한다. 그리고 식별자를 구분하기 위해 equals와 hashCode를 사용해서 동등성 비교를 한다. 식별자 필드가 하나일 때는 보통 자바의 기본 타입을 사용하므로 문제가 없지만, 식별자 필드가 2개 이상이면 별도의 식별자 클래스를 만들고 그곳에 equals와 hashCode를 구현해야 한다.
JPA는 복합 키를 지원하기 위해 @IdClass와 @EmbeddedId 2가지 방법을 제공한다.
@IdClass
Parent 테이블을 보면 기본 키를 PARENT_ID1 과 PARENT_ID2로 묶은 복합 키로 구성했다.
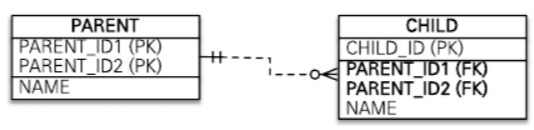
@Entity
@IdClass(ParentId.class)
public class Parent {
@Id
@Column(name = "PARENT_ID1")
private String id1;
@Id
@Column(name = "PARENT_ID2")
private String id2;
private String name;
}public class ParentId implements Serializable {
private String id1;
private String id2;
public ParentId() {}
public ParentId(String id1, String id2) {
this.id1 = id1;
this.id2 = id2;
}
@Override
public boolean equals(Object o) {}
@Override
public boolean hashCode() {}
}
@IdClass를 사용할 때는 식별자 클래스는 다음 조건을 만족해야 한다.
- 식별자 클래스의 속성명과 엔티티에서 사용하는 식별자의 속성명이 같아야 한다.
예제의 Parent.id1 과 ParentId.id1, 그리고 Parent.id2와 ParentId.id2가 같다.
- Serializable 인터페이스를 구현해야 한다.
- equals, hashCode를 구현해야 한다.
- 기본 생성자가 있어야 한다.
- 식별자 클래스는 public 이어야 한다.
실제로 어떻게 사용하는지 알아보자.
Parent parent = new Parent();
parent.setId1("myId1");
parent.setId2("myId2");
parent.setName("parentName");
em.persist(parent);저장 코드에는 ParentId가 보이지 않는데, em.persist()를 호출하면 영속성 컨텍스트에 엔티티를 등록하기 직전에 내부에서 Parent.id1, Parent.id2 값을 사용해서 식별자 클래스인 ParentId를 생성하고 영속성 컨텍스트의 키로 사용한다.
복합 키로 조회해보자.
ParentId parentId = new ParentId("myId1", "myId2");
Parent parent = em.find(Parent.class, parentId);
이제 자식 클래스에 이 복합 키를 외래 키로 추가해보자.
@Entity
public class Child {
@Id
private String id;
@ManyToOne
@JoinColumns({
@JoinColumn(name = "PARENT_ID1",
referenceColumnName = "PARENT_ID1"),
@JoinColumn(name = "PARENT_ID2",
referenceColumnName = "PARENT_ID2")
})
private Parent parent;
}부모 테이블의 기본 키 컬럼이 복합 키 이므로 자식 테이블의 외래 키도 복합 키다. 따라서 외래 키 매핑 시 여러 컬럼을 매핑해야 하므로 @JoinColumns 어노테이션을 사용하고 각각의 이래 키 컬럼을 @JoinColumn으로 매핑한다.
참고로 예제와 같이 name 속성과 referenceColumnName 속성이 같으면 referenceColumnName은 생략해도 된다.
@EmbeddedId
@EmbeddedId는 @IdClass에 비해 좀 더 객체지향적인 방법이다.
@Entity
public class Parent {
@EmbeddedId
private ParentId id;
private String name;
}@Embeddable
public class ParentId implements Serializable {
@Column(name = "PARENT_ID1")
private String id1;
@Column(name = "PARENT_ID2")
private String id2;
// equals 와 hashCode 구현
}
@IdClass와는 다르게 @EmbeddedId를 적용한 식별자 클래스는 식별자 클래스에 기본 키를 직접 매핑한다.
@EmbeddedId는 다음 조건을 만족해야 한다.
- @Embeddable 어노테이션을 붙여야 한다.
- Serializable 인터페이스를 구현해야 한다.
- equals, hashCode를 구현해야 한다.
- 기본 생성자가 있어야 한다.
- 식별자 클래스는 public 이어야 한다.
엔티티를 저장해보자.
Parent parent = new Parent();
ParentId parentId = new ParentId("myId1", "myId2");
parent.setId(parentId);
parent.setName("parentName");
em.persist(parent);
엔티티를 조회해보자. 조회 코드도 식별자 클래스 parentId를 직접 사용한다.
ParentId parentId = new ParentId("myId1", "myId2");
Parent parent = em.find(Parent.class, parentId);
@IdClass VS @EmbeddedId
둘 다 각각 장단점이 있으므로 본인의 취향에 맞는 것을 일관성 있게 사용하면 된다. @EmbeddedId가 @IdClass와 비교해서 더 객체지향적이고 중복이 없어서 좋아보이지만 특정 상황에 JPQL이 조금 더 길어질 수 있다.
복합 키 - 식별 관계 매핑
아래 그림은 부모, 자식, 손자까지 계속 기본 키를 전달하는 식별 관계다.
식별 관계에서 자식 테이블은 부모 테이블의 기본 키를 포함해서 복합 키를 구성해야 하므로 @IdClass나 @EmbeddedId를 사용해서 식별자를 매핑해야 한다.

@IdClass와 식별 관계
@Entity
public class Parent {
@Id @Column(name = "PARENT_ID")
private String id;
private String name;
}
@Entity
@IdClass(ChildId.class)
public class Child {
@Id
@ManyToOne
@JoinColumn(name = "PARENT_ID")
public Parent parent;
@Id @Column(name = "CHILD_ID")
private String childId;
private String name;
}
public class ChildId implements Serializable {
private String parent;
private String childId;
// euqals, hashCode 구현
}
@Entity
@IdClass(GrandChildId.class)
public class GrandChild {
@Id
@ManyToOne
@JoinColumns({
@JoinColumn(name = "PARENT_ID"),
@JoinColumn(name = "CHILD_ID")})
private Child child;
@Id @Column(nmae = "GRANDCHILD_ID")
private String id;
private String name;
}
public class GrandChildId implements Serializable {
private ChildId child;
private String id;
// equals, hashCode 구현
}
식별 관계는 기본 키와 외래 키를 같이 매핑해야 한다. 따라서 식별자 매핑인 @Id와 연관관계 매핑인 @ManyToOne을 같이 사용하면 된다.
Child 엔티티의 parent 필드를 보면 기본 키를 매핑하면서 @JoinColumn과 @ManyToOne으로 외래 키를 같이 매핑했다.
@Id
@ManyToOne
@JoinColumn(name = "PARENT_ID")
public Parent parent;
@EmbeddedId와 식별 관계
@Entity
public class Parent {
@Id @Column(name = "PARENT_ID")
private String id;
private String name;
}
@Entity
public class Child {
@EmbeddedId
private ChildId id;
@MapsId("parentId")
@ManyToOne
@JoinColumn(name = "PARENT_ID")
public Parent Parent;
private String name;
}
@Embeddable
public class ChildId implements Serializable {
private String parentId;
@Column(name = "CHILD_ID")
private String childId;
// euqals, hashCode 구현
}
@Entity
public class GrandChild {
@EmbeddedId
private GrandChildId id;
@MapsId("childId")
@ManyToOne
@JoinColumns({
@JoinColumn(name = "PARENT_ID"),
@JoinColumn(name = "CHILD_ID")})
private Child child;
private String name;
}
@Embeddable
public class GrandChildId implements Serializable {
private ChildId child;
@Column(name = "GRANDCHILD_ID")
private String id;
// equals, hashCode 구현
}
@EmbeddedId는 식별 관계로 사용할 연관관계의 속성에 @MapsId를 사용하면 된다. Child 엔티티의 parent 필드를 보자. @IdClass와 다른 점은 @Id 대신에 @MapsId를 사용한 것이다.
@MapsId("parendId")
@ManyToOne
@JoinColumn(name = "PARENT_ID")
public Parent parent;
비식별 관계로 구현하는 것은 이전 게시글들에서 구현했던 방법대로 구현하면 된다. 복합 키를 사용하지 않기 때문에 복합 키 클래스를 만들 필요도 없다.

일대일 식별 관계
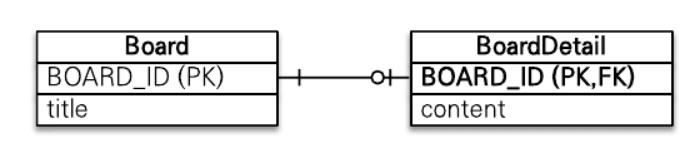
일대일 식별자 관계는 자식 테이블의 기본 키 값으로 부모 테이블의 기본 키 값만 사용한다. 그래서 부모 테이블의 기본 키가 복합 키가 아니면 자식 테이블의 기본 키는 복합 키로 구성하지 않아도 된다.
@Entity
public class Board {
@Id @Generatedvalue
@Column(name = "BOARD_ID")
private Long id;
private String title;
@OneToOne(mappedBy = "board")
private BoardDetail boardDetail;
}
@Entity
public class BoardDetail {
@Id
private Long boardId;
@MapsId
@OneToOne
@JoinColumn(name = "BOARD_ID")
private Board board;
private String content;
}
BoardDetail처럼 식별자가 단순히 컬럼 하나면 @MapsId를 사용하고 속성 값은 비워둔다. 이때 @MapsId는 @Id를 사용해서 식별자로 지정한 BoardDetail.boardId와 매핑된다.
식별, 비식별 관계의 장단점
데이터베이스 설계 관점에서 보면 아래와 같은 이유로 식별 관계보다는 비식별 관계를 선호한다.
- 식별 관계는 부모 테이블의 기본 키를 자식 테이블로 전파하면서 자식 테이블의 기본 키 컬럼이 점점 늘어난다.
- 식별 관계는 2개 이상의 컬럼을 합해서 복합 기본 키를 만들어야 하는 경우가 많다.
- 식별 관계를 사용할 때 기본 키로 비즈니스 의미가 있는 자연 키 컬럼을 조합하는 경우가 많다. 비즈니스 요구사항은 시간이 지남에 따라 언젠가는 변한다. 식별 관계의 자연 키 컬럼들이 손자까지 전파되면 변경하기 힘들다.
- 식별 관계는 부모 테이블의 기본 키를 자식 테이블의 기본 키로 사용하므로 비식별 관계보다 테이블 구조가 유연하지 못하다.
객체 관계 매핑의 관점에서 보면 아래와 같은 이유로 비식별 관계를 선호한다.
- 일대일 관계를 제외하고 식별 관계는 2개 이상의 컬럼을 묶은 복합 기본 키를 사용한다. JPA에서 복합 키는 별도의 복합 키 클래스를 만들어서 사용해야 하낟. 따라서 컬럼이 하나인 기본 키를 매핑하는 것보다 많은 노력이 필요하다.
- 비식별 관계의 기본 키는 주로 대리 키를 사용하는데 JPA는 @GeneratedValue처럼 대리 키를 생성하기 위한 편리한 방법을 제공한다.
식별 관계가 주는 장점도 있다. 기본 키 인덱스를 활용하기 좋고, 상위 테이블들의 기본 키 컬럼을 자식, 손자 테이블이 가지고 있으므로 특정 상황에 조인 없이 하위 테이블만으로 검색을 완료할 수 있다.
ORM 신규 프로젝트 진행 시 추천 방법은 비식별 관계로 기본 키는 Long 타입의 대리 키를 사용하는 것이다.
Long을 추천하는 이유는 자바에서 Integer는 20억 정도면 끝나기에 데이터를 많이 저장하면 문제가 생길 수 있기 때문이다.
그리고 필수적 비식별 관계를 사용하는 것이 좋다. 선택적 비식별 관계는 null을 허용하므로 외부 조인을 사용해야하는데 필수적 비식별 관계는 항상 관계가 있으므로 내부 조인을 사용해도 된다.
조인 테이블
데이터베이스 테이블의 연관관계를 설계하는 방법은 2가지이다.
1. 조인 컬럼 사용 (외래 키)
2. 조인 테이블 사용 (테이블 사용)
조인 컬럼 사용
테이블 간에 관계는 주로 조인 컬럼이라 부르는 외래 키 컬럼을 사용해서 관리한다.
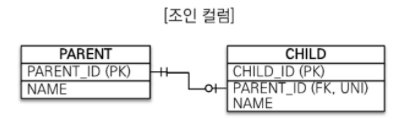
조인 테이블 사용
이 방법은 조인 테이블이라는 별도의 테이블을 사용해서 연관관계를 관리한다.
위 아래 그림을 비교해보면 조인 컬럼을 사용하는 방법과 조인 테이블을 사용하는 방법의 차이를 알 수 있다.

조인 컬럼을 사용하는 방법은 단순히 외래 키 컬럼만 추가해서 연관관계를 맺지만 조인 테이블을 사용하는 방법은 연관관계를 관리하는 조인 테이블을 추가하고 이 테이블에서 두 테이블의 외래 키를 가지고 연관관계를 관리한다. 따라서 member와 locker에는 연관관계를 관리하기 위한 외래 키 컬럼이 없다.
조인 테이블의 가장 큰 단점은 테이블을 하나 추가해야 한다는 점이다. 따라서 관리해야 하는 테이블이 늘어나고 회원과 사물함 두 테이블을 조인하려면 member_locker 테이블까지 추가로 조인해야 한다.
따라서 기본은 조인 컬럼을 사용하고 필요할 때 조인 테이블을 사용하자.
- 객체와 테이블을 매핑할 때, 조인 컬럼은 @JoinColumn, 조인 테이블은 @JoinTable을 사용한다.
- 조인 테이블은 주로 다대다 관계를 일대다, 다대일 관계로 풀어내기 위해 사용한다. 그렇지만 일대일, 일대다, 다대일 관계에서도 사용될 수 있다.
일대일 조인 테이블
일대일 관계를 만들려면 조인 테이블의 외래 키 컬럼 각각에 총 2개의 유니크 제약조건을 걸어야 한다.
@Entity
public class Parent {
@Id @GeneratedValue
@Column(name = "PARENT_ID")
private Long id;
private String name;
@OneToOne
@JoinTable(name = "PARENT_CHILD",
joinColumns = @JoinColumn(name = "PARENT_ID"),
inverseJoinColumns = @JoinColumn(name = "CHILD_ID"))
private Child child;
}
@Entity
public class Child {
@Id @GeneratedValue
@Column(name = "CHILD_ID")
private Long id;
private String name;
}부모 엔티티를 보면 @JoinColumn 대신에 @JoinTable을 사용했다.
@JoinTable의 속성
- name : 매핑할 조인 테이블 이름
- joinColumns : 현재 엔티티를 참조하는 외래 키
- inverseJoinColumns : 반대방향 엔티티를 참조하는 외래 키
양방향 매핑 시 아래를 추가하면 된다.
public class Child {
@OneToOne(mappedBy = "child")
private Parent parent;
}
일대다 조인 테이블
일대다 관계를 만들려면 조인 테이블의 컬럼 중 다와 관련된 컬럼인 CHILD_ID에 유니크 제약조건을 걸어야 한다. (CHILD_ID는 기본 키이므로 유니크 제약 조건이 걸려 있다.)
@Entity
public class Parent {
@Id @GeneratedValue
@Column(name = "PARENT_ID")
private Long id;
private String name;
@OneToMany
@JoinTable(name = "PARENT_CHILD",
joinColumns = @JoinColumn(name = "PARENT_ID"),
inverseJoinColumns = @JoinColumn(name = "CHILD_ID"))
private List<Child> childs = new ArrayList<>();
}
@Entity
public class Child {
@Id @GeneratedValue
@Column(name = "CHILD_ID")
private Long id;
private String name;
}
다대일 조인 테이블
다대일은 일대다에서 방향만 반대이므로 조인 테이블 모양은 일대다와 동일하다.
@Entity
public class Parent {
@Id @GeneratedValue
@Column(name = "PARENT_ID")
private Long id;
private String name;
@OneToMany(mappedBy = "parent")
private List<Child> childs = new ArrayList<>();
}
@Entity
public class Child {
@Id @GeneratedValue
@Column(name = "CHILD_ID")
private Long id;
private String name;
@ManyToOne(optional = false)
@JoinTable(name = "PARENT_CHILD",
joinColumns = @JoinColumn(name = "PARENT_ID"),
inverseJoinColumns = @JoinColumn(name = "CHILD_ID"))
private Parent parent;
}
다대다 조인 테이블
다대다 관계를 만들려면 조인 테이블의 두 컬럼을 합해서 하나의 복합 유니크 제약 조건을 걸여아 한다.
@Entity
public class Parent {
@Id @GeneratedValue
@Column(name = "PARENT_ID")
private Long id;
private String name;
@ManyToMany
@JoinTable(name = "PARENT_CHILD",
joinColumns = @JoinColumn(name = "PARENT_ID"),
inverseJoinColumns = @JoinColumn(name = "CHILD_ID"))
private List<Child> childs = new ArrayList<>();
}
@Entity
public class Child {
@Id @GeneratedValue
@Column(name = "CHILD_ID")
private Long id;
private String name;
}
엔티티 하나에 여러 테이블 매핑
잘 사용하지는 않지만 @SeceondaryTable을 사용하면 한 엔티티에 여러 테이블을 매핑할 수 있다.
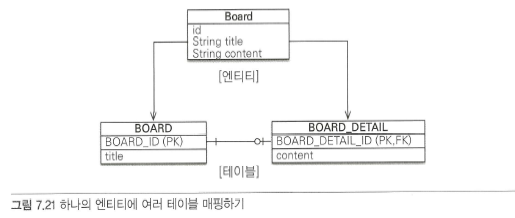
하나의 엔티티에 여러 테이블을 매핑해보자.
@Entity
@Table(name = "BOARD")
@SecondaryTable(name = "BOARD_DETAIL",
pkJoinColumns = @PrimaryKeyJoinColumn(name = "BOARD_DETAIL_ID"))
public class Board {
@Id @GeneratedValue
@Column(name = "BOARD_ID")
private Long id;
private String title;
@Column(table = "BOARD_DETAIL")
private String content;
}
@SecondaryTable.name : 매핑할 다른 테이블 이름
@SecondaryTable.pkJoinColumns : 매핑할 다른 테이블의 기본 키 컬럼 속성
@Column(table = "BOARD_DETAIL") : content 필드는 BOARD_DETAIl 테이블의 컬럼에 매핑했다. title과 같이 테이블을 지정하지 않으면 기본 테이블인 BOARD와 매핑된다.
더 많은 테이블을 이용하려면 @SecondaryTables를 이용한다.
'🍀spring > 스프링 jpa' 카테고리의 다른 글
| [Spring JPA] 값 타임 (0) | 2024.03.03 |
|---|---|
| [Spring JPA] 프록시와 연관관계 관리 (0) | 2024.03.03 |
| [Spring JPA] 다양한 연관관계 매핑 (1) | 2024.02.29 |
| [Spring JPA] 연관관계 매핑 기초 (1) | 2024.02.28 |
| [Spring JPA] 엔티티 매핑 (1) | 2024.02.26 |